| Remarque | ||
|---|---|---|
| ||
Cette documentation, qui date de 2017 et porte sur Grouper 2.3, doit être considérée comme en partie obsolète, même si certaines informations restent intéressantes à consulter, comme le parapgraphe "Contexte d'usage et intégration souhaitée de Grouper dans le SI de l'établissement" par exemple. |
Introduction
Après plusieurs années d'utilisation dans différents établissements, Grouper d'Internet2 est considéré comme une solution de gestion de groupes mature et satisfaisante ; notamment dans sa version actuelle, la 2.3.0.
...
Toujours à l'image de ce qui avait été proposé lors du Workshop Grouper 2.1.5 – 15/04/2014 – Paris Descartes , nous vous proposons une VM (téléchargement disponible depuis la page VM Grouper, Shibboleth, LDAP) sous virutalbox complètement autonome !
Cela vous permet ainsi d'avoir à disposition une installation complète de grouper qui fonctionne. Pour la partie Grouper, cette VM a été réalisée en suivant cette documentation. Elle embarque un IdP Shibboleth (v3) et un (open)LDAP Supann.
Une page spécifique donne quelques indications sur celle-ci : VM Grouper, Shibboleth, LDAP
Plan du document
| Sommaire |
|---|
Version de Grouper
La version de Grouper actuellement traitée par ce document est la 2.3.0.
Contexte d'usage et intégration souhaitée de Grouper dans le SI de l'établissement.
Le contexte d'usage et l'intégration de Grouper dans le système d'information de l'établissement sont contraints de cette façon :
- authentification shibboleth sur les interfaces web Grouper - même si ici seuls les personnels de l'établissement sont amenés à s'authentifier sur celles-ci dans cette configuration.
- le LDAP de l'établissement est un openldap basé sur les recommandations (et schémas) Supann
- les potentiels membres des groupes (source des individus pour grouper) sont tous issus du LDAP de l'établissement et on utilise comme identifiant non pas leur uid ldap mais leur eppn (eduPersonPrincipalName)
les groupes sont poussés/synchronisés dans le Ldap comme groupOfNames ('plus supann' et ‘plus standard’ que les posixGroup) côté ou=groups et éventuellement (conseillé) memberOf côté ou=people (via un overlay) par Grouper
- la nomenclature des groupes dans ldap reprend la nomenclature hiérarchique des groupes de Grouper - les ":" sont transformés en "." dans le passage de l'id de Grouper au dn ldap
- les applications utilisant les groupes ne conversent pas avec Grouper mais avec LDAP (cf schéma ci-dessous)
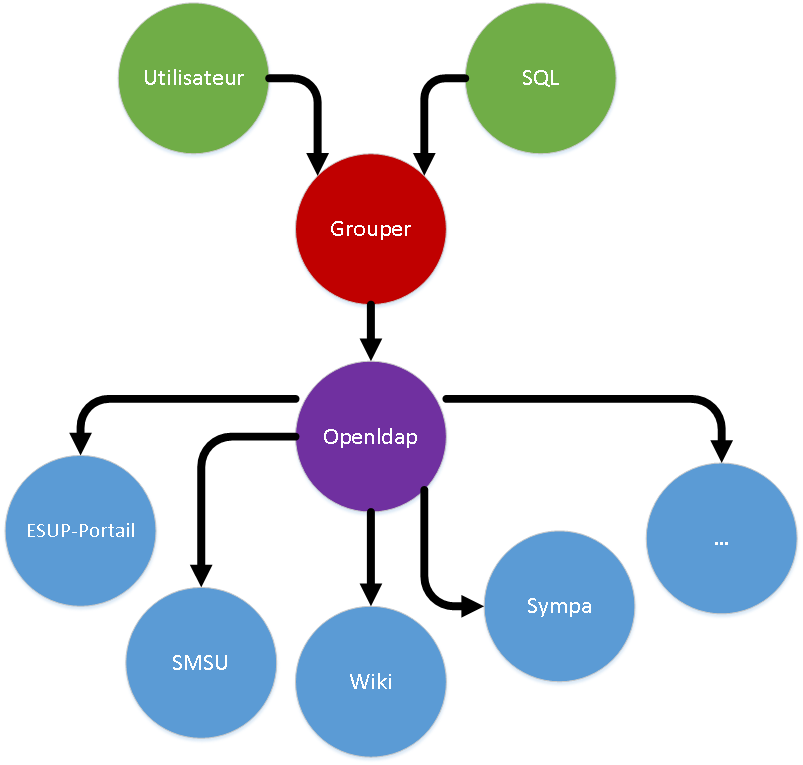
LDAP, prérequis/ajustements techniques
L'intégration de Grouper dans le Système d'Information est portée par l'annuaire LDAP openldap construit selon les recommandations supann.
Des ajustements techniques doivent/peuvent être effectués (si non présents dans votre ldap).
overlay memberOf
Pour faciliter l'usage des groupes ldap dans les applications, il est intéressant de proposer l'information d'appartenance d'un individu à un groupe dans l'object de l'individu (supannPerson positionné dans ou=people) en plus de cette information portée par le groupOfNames (supannGroupe) lui-même.
...
Vous pouvez suivre cette documentation par exemple : http://idmoim.blogspot.fr/2014/05/enabling-memberof-attribute-in-openldap.html
Indexes
Pour optimiser les performances des applicatifs et de Grouper on vous conseille d'ajouter des indexes, notamment sur
...
https://www.vincentliefooghe.net/content/ajout-dindex-sur-un-annuaire-openldap
Tri des attributs member
Sur des groupes de plusieurs milliers ou dizaines de milliers d'individus, il est impératif que l'attribut member soit trié, notamment pour que la suppression d'un individu à un groupe ne pose pas de problème.
...
| Info | ||
|---|---|---|
| ||
Cet ajustement de tri est effectivement utile lorsqu'on utilise un backend comme BDB (Berkeley DataBase) Avec d'autres moteurs plus récents/évolués comme LMDB, il semblerait que ce ne soit plus nécessaire. Ce backend plus récent se montre plus performant ; openldap recommande maintenant son usage : https://www.vincentliefooghe.net/content/openldap-changer-moteur-backend |
Ajustement de la RAM pour openldap avec LMDB
Rappel : cf plus haut, (L)MDB est recommandé et est maintenant le backend donné par défaut dans la plupart des distributions.
- LMDB monte la base en RAM pour pouvoir l'exploiter ;
- grouper fait des requêtes assez conséquentes (1 pour trouver un groupe puis 1 par membre d'un groupe) qui, si vous avez des groupes comprenant finalement l'ensemble des individus, correspondent finalement à requêter très régulièrement toute la base ;
- les requêtes, notamment sur les membres, sont mises en cache par grouper (via ehcache) en RAM ...
- on peut ajuster cette configuration d'ehcache
- cependant, le script export-modified-groups-to-LDAP fonctionne en lançant une nouvelle instance de gsh (== grouper) à chaque modification de groupe : le cache ehcache de grouper est alors impuissant
- si votre serveur LDAP dispose d'un espace RAM plus petit que la taille de votre base, alors :
- LMDB se verra contraint de flusher une partie de la base pour monter la partie qui qu'il doit lire et qu'il n'avait pas pu monter en RAM faut faute d'espace ; si vous consultez l'ensemble de la base trtès très régulièrement, vous provoquez ce mécanisme de manière cyclique !
- en conséquence, vous pouvez alors constater un usage du disque en lecture (IO READ) très important.
→ en LMDB, et notamment avec grouper qui peut solliciter beaucoup le ldap, il est vivement recommandé de fournir assez de RAM au serveur pour que l'ensemble de la base (ou au moins la base "utile") puisse être monté en RAM :
en disposant d'un volume de RAM supérieur à la taille (effective) du .mdb (dans /var/lib/ldap/ généralement), on s'assure déviter d'éviter de l'IO (lecture) trop important. Privilégier Privilégiez également des disques SSD pour les VMs du LDAP (imports LDIFs et réindexations).
Pour avoir la taille effective: ll -sh *mdb
1,9G -rw------- 1 openldap openldap 6,6G nov. 8 12:06 data.mdb
4,0K -rw------- 1 openldap openldap 8,0K nov. 8 12:08 lock.mdb
Dimensionnement serveurs
Le service Grouper peut fonctionner sur un unique serveur sur lequel on fait tourner
...
Pour la disponibilité du service, notre contexte d'usage fait qu'une indisponibilité de Grouper ne permet plus de mettre à jour les groupes simplement. L'usage des groupes par les applicatifs est en effet porté par LDAP.
Une indisponibilité de Grouper n'est donc pas critique.
Éléments techniques à installer sur le serveur qui héberge Grouper.
Java / Tomcat
Les service Grouper correspondent à des applications Java / Tomcat.
Ceux-ci fonctionnent avec un JDK 1.7 8 et Tomcat 69.
- vous pouvez prendre le JDK iun OpenJDK 1.7 distribué par Oracle ou plutôt (recommandation) la version openjdk 1.7 de votre distribution (yum install java-1.7.0-openjdk-devel pour CentOs 7) ... en effet, le JDK 1.7 distribué par Oracle n'est plus disponible/maintenu publiquement (gratuitement).8, par exemple celui distribué par Azul pour debian - https://docs.azul.com/core/install/debian
- pour Tomcat, prenez la dernière version 6 9 proposée - https://archive.apache.org/dist/tomcat/tomcat-6/v6.0.39/bin/9/?C=M;O=D
Pour construire les binaires depuis les sources, nous avons également besoin de ANT
Ant
Si vous avez installé le JDK de votre distribution, installez dans la foulée le Apache Ant de la même façon (yum apt install ant pour CentOS 7Debian).
Java
On édite un fichier /opt/grouper-env qui est un fichier d'environnement utilisé par les différents scripts de démarrage de service et par un utilisateur 'grouper' (à créer) sous lequel on travaille (lancement du tomcat, scripts de synchro, client shell grouper).
...
| Bloc de code |
|---|
. /opt/env.sh |
Tomcat
Dézippez le tomcat dans /opt et faites le appartenir à l'utilisateur 'grouper'.
...
| Bloc de code |
|---|
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" tomcatAuthentication="false"/> |
PostgreSQL
Grouper utilise une base de données SQL. Installez le serveur postgresql fourni par votre distribution puis créez une base pour grouper :
| Bloc de code |
|---|
create database grouper; create USER grouper with password 'esup'; grant ALL ON DATABASE grouper to grouper; |
Apache et mod_shib
Comme pour la plupart des applications 'shibbolethisées', l'authentification/identification shibboleth est effectuée par Apache et le mod_shib.
...
| Bloc de code |
|---|
<VirtualHost *:80>
ServerName grouper.univ-ville.fr
ServerAlias grouper
ErrorLog /var/log/apache2/error.log
CustomLog /var/log/apache2/access.log combined
Redirect / https://grouper.univ-ville.fr/
</VirtualHost>
<VirtualHost *:443>
ServerName grouper.univ-ville.fr
ServerAlias grouper
LogLevel warn
ErrorLog /var/log/apache2/error.log
CustomLog /var/log/apache2/access.log combined
ErrorDocument 503 /503/index.html
ProxyPass /503 !
RewriteEngine On
RewriteRule ^/$ /grouper [L,R,NE]
SSLEngine on
ProxyPass /Shibboleth.sso !
ProxyPass /secure !
ScriptAlias /secure /var/www/printenv.pl
<Location /secure>
AuthType shibboleth
ShibRequestSetting requireSession 1
require shib-session
ShibUseHeaders On
</Location>
<Location /grouper>
AuthType shibboleth
ShibRequestSetting requireSession 1
require shib-session
ShibUseHeaders On
</Location>
ProxyPass / ajp://localhost:8009/ ttl=10 timeout=3600 retry=1
</VirtualHost> |
Grouper ESUP
Le 'fork' ESUP est disponible depuis le repository github Esup https://github.com/EsupPortail/grouper-esup - vous noterez qu'il est bien vu comme un fork de Grouper d'Internet2 au niveau de Github.
...
Cette version correspond à une véritable installation de Grouper dans un établissement, nous avons simplement renommé les noms des serveurs, changé les mots de passe, ... ce "paramétrage" que l'on a fait tenir en un seul commit correspond à un travail conséquent de plusieurs établissements que l'on remercie énormément.
Récupération de la version Grouper d'Esup
| Bloc de code |
|---|
cd /opt git clone https://github.com/EsupPortail/grouper-esup.git |
Modifications apportées
La commande suivante vous permet d'avoir une bonne idée des fichiers modifiés ou ajoutés par rapport au tag GROUPER_2_3_0 récupéré initialement et utilisé donc comme point de départ :
...
Les modifications des fichiers ci-dessus correspondent à du paramétrage LDAP sauf pour grouper/conf/grouper-loader.properties.
| Info | ||
|---|---|---|
| ||
grouper-loader.properties permet en effet de paramétrer des bases de données permettant de réaliser des groupes dynamiques par requettages sql (ces requêtes étant données / paramétrées via l'interface homme machine). Une fois votre Grouper installé, c'est le seul fichier que vous aurez à modifier de temps en temps pour pouvoir requêter de nouvelles bases de données ; la requête en elle-même est saisi dans l'IHM mais pas les paramètres d'accès aux bases de données ... en tout cas en Grouper 2.3 car en 2.4 il se pourrait que ce soit une nouvelle possibilité de l'IHM de Grouper ! |
...
Vous aurez également besoin de modifier éventuellement les autres fichiers comme grouper/conf/grouper.hibernate.properties par exemple si vous avez pris un autre mot de passe ou nom de base que ceux indiqués ci-dessus ...
Jars supplémentaires
...
Déploiement
Pour que les modifications de fichiers (configurations) soient prises en compte, en plus de redémarrer les services Grouper (au sens unix / daemon; cf ci-dessous cela correspond aux services tomcat-grouper.service, grouper-loader-daemon.service et export-modified-groups-to-LDAP.service) vous devez redéployer les briques Grouper.
Vous stoppez les 3 services Grouper puis vous lancez successivement les redéploiements suivants :
| Bloc de code |
|---|
cd /opt/grouper-esup/grouper-ui/ ant clean dist cd /opt/grouper-esup/grouper-ws/grouper-ws/ ant clean dist |
Vous redémarrez les 3 services précédemment stoppés.
Présent dans les sources Grouper, nous avons ici déployé naturellement grouper-ws ... même si celui-ci est complètement optionnel. Si vous ne vous en servez pas, vous n'êtes donc pas obligé de le déployer et de déclarer son contexte dans la configuration tomcat.
Tâches d'exploitation
Scipts de démarrage
L'installation des services postgresql, apache, sp shibboleth ont dû engendrer l'ajout des scripts de démarrages (initd/systemctl/systemd).
Il faut y ajouter les services installés 'manuellement'. Sous Centos 7 on Debian on a ainsi :
- /usretc/lib/systemd/system/tomcat-grouper.service
| Bloc de code |
|---|
# Systemd unit file for tomcat [Unit] Description=Apache Tomcat Web Application Container After=syslog.target network.target [Service] Type=forking EnvironmentFile=/opt/grouper-env Environment=CATALINA_PID=/opt/tomcat-grouper/temp/tomcat.pid Environment=CATALINA_HOME=/opt/tomcat-grouper ExecStart=/opt/tomcat-grouper/bin/startup.sh ExecStop=/bin/kill -15 $MAINPID User=grouper Group=grouper [Install] WantedBy=multi-user.target |
- /usr/libetc/systemd/system/grouper-loader-daemon.service
| Bloc de code |
|---|
# Systemd unit file for grouper-loader-daemon [Unit] Description=Synchro incrementale grouperloader (bases de données) vers grouper After=syslog.target network.target [Service] EnvironmentFile=/opt/grouper-env ExecStart=/opt/grouper-esup/grouper/bin/grouper-loader-daemon User=grouper Group=grouper [Install] WantedBy=multi-user.target |
/usr/libetc/systemd/system/export-modified-groups-to-LDAP.service
...
Vérifiez dans /var/log/messages la bonne exécution de l'ensemble. Pour une bonne mise en oeuvre de ces services, vous pouvez les tester individuellement avec l'utilisateur grouper en les lançant depuis une console directement.
En effet, certains scripts peuvent requérir la présence de certaines bibliothèques supplémentaires : export-modified-groups-to-LDAP est un script perl qui utilise des bibliothèques perl comme DBI ou encore DBD-PG (yum install perl-DBI perl-DBD-Pg pour Centos).
Backup de la BD
Pour sauvegarder votre base de données de manière consistante, ajoutez un dump postgresql dans /etc/crontab simplement pour que le dump soit fait avant le passage de votre robot de sauvegarde.
...
| Bloc de code |
|---|
mkdir /opt/backup && chown -R postgres:postgres /opt/backup |
Tâches CRON de synchronisation
Pour assurer les synchronisations au mieux, on ajoute également dans /etc/crontab :
| Bloc de code |
|---|
# Synchro ldap totale toutes les heures - consolide la synchro incrémentale effectuée par export-modified-groups-to-LDAP.service 15 * * * * grouper /opt/grouper-esup/grouper/bin/gsh-psp-bulkSync # redémarrage de grouper-loader-daemon.service pour prise en compte ajout/modif groupes dynamiques 00,30 * * * * root systemctl restart grouper-loader-daemon.service |
Démarrage de Grouper et prise en main
Initialisation de la base de données de Grouper
On initialise la base de données avec gsh ainsi :
...
Le script initialise la base de données, on peut voir dans postgresql que la base grouper contient plus de 100 tables.
Peuplement du groupe etc:sysadmingroup
Une fois Grouper démarré, vous pourrez l'utiliser via ses interfaces web directement. Pour ce faire cependant, vous avez besoin de vous déclarer comme administrateur de Grouper. Vous faites cela en démarrant un shell grouper, en créant le groupe configuré comme étant le groupe des administrateurs et en ajoutant votre user à ce groupe :
| Bloc de code |
|---|
/opt/grouper-esup/grouper/grouper/bin$ ./gsh.sh
gsh 0% addGroup("etc", "sysadmingroup", "Administrateurs de Grouper")
gsh 1% addMember("etc:sysadmingroup", "joe@univ-ville.fr") |
Démarrage des services
| Bloc de code |
|---|
systemctl restart tomcat-grouper.service systemctl restart grouper-loader-daemon.service systemctl restart export-modified-groups-to-LDAP.service |
Interface Web
Vous pouvez maintenant utiliser votre Grouper et initier votre arborescence de groupes.
...
Dans un tout premier temps, un groupe à créer peut être le groupe DSI qui sera membre de etc:sysadmingroup par exemple !
Usage de Grouper
L'objet de ce document n'est pas de faire une documentation de Grouper véritablement, l'idée est juste de faciliter son installation et sa mise en œuvre.
...
- réaliser des groupes dynamiques issus de requêtes sql sur des bases externes : https://spaces.internet2.edu/display/Grouper/Grouper+-+Loader
- réaliser des groupes composites : https://spaces.internet2.edu/display/Grouper/Grouper+UI+composites
- accorder des privilèges à un utilisateur ou à un groupe sur un dossier incluant tous les sous-dossiers et sous-groupes : https://spaces.internet2.edu/display/Grouper/Grouper+rules+privileges+inheritance+on+UI
- purger les membres supprimés dans le ldap mais affectés à des groupes dans grouper ('Entity not found') : https://spaces.at.internet2.edu/pages/viewpage.action?pageId=14517820
- ...
...