Introduction
Après maintenant quelques années d'utilisation dans différents établissements, Grouper d'Internet2 est à l'usage une solution satisfaisante de gestion de groupes.
D'architecture complexe mais complète, sa mise en place dans un établissement n'est pas des plus simples, mais une fois en fonctionnement, Grouper d'Internet2 est une solution qui se fait aprécier.
Son installation et sa configuration sont en effet complexes, à sa décharge Grouper est hautement configurable et peut s'adapter à des cas d'usages avancés et très variés.
Dès les prémices de l'installation plusieurs choix s'offrent à l'intégrateur : installation depuis Grouper Installer, depuis une archive, depuis les sources, ...
Les possibilités de configuration et de mises en place des synchros sont ensuite sujets également à bon nombre de variantes.
A côté de cela, l'uniformisation croissante de nos Systèmes d'Information (supann, openldap, shibboleth, férédation d'identités, CAS) ainsi que les expériences et retours des établissements ayant sauté le pas (cf Contributions d'établissements et présentations ESUP-Days n°20, ESUP-Days n°22, ...) nous ont conforté dans l'idée que nos installations de Grouper pouvaient être assez similaires dans nos établissements.
La gestion d'un package Grouper 'ESUP' nous parait cependant trop ambitieuse et à terme contre-productive.
Aussi avons-nous décidé d'élaborer une documentation se voulant simple, concise, efficace et répondant à un contexte d'usage très spécifique et restreint : usage simple constaté dans nos établissements jusque-là.
Pour faciliter l'installation de Grouper, ce document propose d'utiliser une archive* contenant une installation de Grouper (correspondant initialement à l'installation de l'Université de Paris1) à reparamétrer. Ce document vous indique ce qu'il faut reparamétrer.
Une fois que vous avez une installation "simple" et fonctionnelle intégrée dans votre système d'information, libre à vous par la suite d'aller plus loin dans l'usage de Grouper.
Gouper peut cependant tout à fait convenir et rendre énormément de servicies dans un usage circonscrit comme proposé ici ; cette intégration ayant alors le mérite de rester relativement simple, de ne pas sortir des clous par rapport à ce qui se fait "basiquement" avec Grouper ; on retire alors les avantages d'une maintenance facilitée par exemple.
*Nous avons envisagé de refaire une VM sous virutalbox telle que proposée lors du Workshop Grouper 2.1.5 – 15/04/2014 – Paris Descartes.
Vu le temps de mise en place qu'une telle entreprise prend nous hésitons à nous lancer dans cette tâche. On hésite également à utiliser plutôt d'autres solutions telles que Vagrant, Docker ou Ansible ...
Plan du document
Contexte d'usage et intégration souhaitée de Grouper dans le SI de l'établissement.
Le contexte d'usage et l'intégration de Grouper dans le système d'information de l'établissement est contraint de cette façon :
- authentification shibboleth sur les interfaces web Grouper - même si ici seuls les personnels de l'établissement sont amenés à s'authentifier sur celles-ci
- le LDAP de l'établissement est un openldap basé sur les recommandations (et schéma) Supann
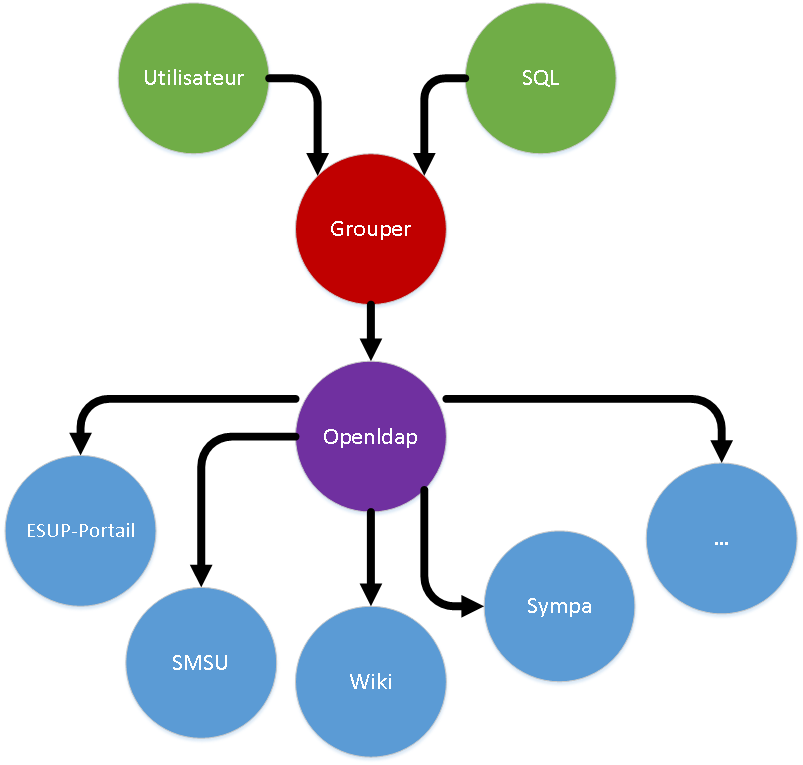
- les potentiels membres des groupes (sources des individus pour grouper) sont tous issus du LDAP de l'établissement et on utilise comme identifiant non pas leur uid ldap mais leur eppn (eduPersonPrincipalName)
les groupes sont poussés/synchronisés dans le Ldap comme groupOfNames ('plus supann' et ‘plus standard’ que les posixGroup) côté ou=groups et éventuellement (conseillé) memberOf côté ou=people (via un overlay) par Grouper
- la nomenclature des groupes dans ldap reprend la nomenclature hiérarchique des groupes de grouper - les ":" sont transormés en "." dans le passage de l'id de grouper au dn ldap
- les applications utilisant les groupes ne conversent pas avec Grouper mais avec LDAP (cf schéma ci-dessous)
LDAP, prérequis/ajustements techniques
L'intégration de Grouper dans le Système d'Information est ici portée votre annuaire LDAP openldap construit selon les recommandations supann.
Des ajustements techniques doivent/peuvent être effectués (si ils n'ont pas déjà été faits).
overlay memberOf
Pour faciliter l'usage des groupes ldap dans les applications, il est intéressant de proposer l'information d'appartenance d'un individu à un groupe dans l'object de l'individu (supannPerson positionné dans ou=people) en plus de cette information portée par le groupOfNames (supannGroupe) lui-même.
Pour ce faire, l'idée est de mettre enplace le overlay memberOf.
Vous pouvez suivre cette documentation par exemple : http://idmoim.blogspot.fr/2014/05/enabling-memberof-attribute-in-openldap.html
Indexes
Pour optimiser les performances des applicatifs et de Grouper on vous conseille d'ajouter également des indexes, notamment sur
- eduPersoPrincipalName et memberOf côté ou=people
- member côte ou=groups
https://www.vincentliefooghe.net/content/ajout-dindex-sur-un-annuaire-openldap
Tri des attributs member
Sur des groupes de plusieurs milliers ou dizaines de milliers d'individus, il est impératif que l'attribut member soit trié, notamment pour que la suppression d'un individu à un groupe ne pose pas de problème.
Il faut donc demander à openldap de trier (olcSortVals) cet attribut member ... sous peine d'obtenir des temps de réponse catastrophiques, de récupérer des DB_LOCK_DEADLOCK au niveau de la base ldap, voir de mettre à terre votre serveur ldap !
Pour ce faire, vous pouvez suivre cette documentation :
Eléments techniques à installer sur le serveur qui héberge Grouper.
Java
PostgreSQL
Apache et mod_shib
Archive ESUP consituant le service Grouper
On décrit rapidement les éléments à modifier pour que cela s'intègre à votre SI (principalement LDAP).
Tâches d'exploitation
Backup de la BD
Tâches CRON de synchronisation