Prérequis : environnement technique mis en place
2.1 Sources
2.1.1 Solution 1 : Installation rapide à l'aide du .war livré
La personnalisation de l'application n'est pas prévue pour cette installation (personnalisation fine du css, utilisation de beans java propres, etc..). Les étapes spécifiques à cette solution seront notées SOLUTION 1 dans le reste du document.
- Récupérer le war de la dernière version de DossierWeb-V3 sur https://github.com/EsupPortail/esup-mdw/releases
2.1.2 Solution 2 : Installation personnalisée
La personnalisation de l'application est prévue pour cette installation (personnalisation fine du css, utilisation de beans java propres, etc..). Les étapes spécifiques à cette solution seront notées SOLUTION 2 dans le reste du document.
- Récupérer le zip 'distribution' de la dernière version de DossierWeb-V3 sur https://github.com/EsupPortail/esup-mdw/releases
- Dézipper l'archive dans un dossier puis passer au paramétrage de l'application
2.2 Paramétrage
2.2.1 Paramétrage de l'application
- Copier ou renommer le fichier context.sample.xml en context.xml. Y renseigner les paramètres ci-dessous et placer le fichier context.xml dans le répertoire /conf de Tomcat.
- Suivant le choix de la solution dans la partie 2.1, le fichier context.sample.xml se trouve :
- SOLUTION 1 : dans META-INF/ (peut également être placé dans le répertoire 'conf' de tomcat)
- SOLUTION 2 : dans /src/main/webapp/META-INF/
- SOLUTION 1 : dans META-INF/ (peut également être placé dans le répertoire 'conf' de tomcat)
- Suivant le choix de la solution dans la partie 2.1, le fichier context.sample.xml se trouve :
| Propriété | Définition |
|---|---|
| jdbc/dbMdw | Déclaration de votre base de données MySql de monDossierWeb |
| jdbc/dbApogee | Déclaration de votre base de données Apogée (pour le requêtage direct sur la base)
|
| clefApogeeDecryptBlob | Clé Apogée pour décrypter les Blob de la base Apogée (ex : signature certificat de scolarité) Pour information, cette clé est visible dans le package PKB_CRY2 |
| app.url | Url de l'application |
| startServletMobile | true pour démarrer la servlet mobile, false ne proposer que la vue desktop |
| cas.url | Url de votre service d'authentification CAS. Ex : https://auth.univ-ville.fr (l'application ajoute automatiquement /login) |
ldap.url ldap.userDn ldap.password ldap.uid.attribute ldap.ou.people ldap.ou.student | Informations de connexion au ldap, respectivement :
|
uportal.ws uportal.groupes.autorises | Configuration de l'authentification des enseignants via les groupes uPortal de l'ENT
|
loginApogee checkTesUtilisateurApogee profilUtilisateurApogee | Configuration de l'authentification des enseignants via la table UTILISATEUR d'Apogée
|
attributGroupeLdap listeGroupesLdap listeGroupesLdapAdmin | Configuration de l'authentification des enseignants via des groupes LDAP
|
attributLdapEtudiant typeEtudiantLdap attributLdapCodEtu | Configuration de l'authentification des étudiants
|
attributLdapDoctorant valeursAttributLdapDoctorant | Permet d'identifier les utilisateurs pour lesquels on souhaite prioritairement vérifier si l'attribution du profil "enseignant" est possible. Sans ce paramétrage, les utilisateurs cibles auraient obtenus le profil "etudiant". Typiquement le cas des doctorants (pouvant également effectuer de l'enseignement)
|
attributLdapGestionnaire valeursAttributLdapGestionnaire | Permet d'identifer les utilisateurs auxquels attribuer le profil "gestionnaire"
|
apoWsUsername apoWsPassword | Indiquer de manière facultative un utilisateur des WebServices Apogée lors des appels aux WebServices Apogée (voir roles.xml et users.xml dans la configuration des WebServices). Attention : Un utilisateur correctement authentifié auprès du WebService doit possèder au moins un des rôles nécessaires à l'appel des méthodes utilisées par MDW, même si la méthode autorise le rôle "anonymous". Dans ce cas, le user défini dans users.xml devra possèder le rôle ROLE_ANONYMOUS. |
| sourceResultats | Source des résultats lors de l'appel aux Web Services Apogée pour récupérer les notes et résultats
|
| productionMode | Mode production. Doit être à true |
| debugMode | Active les traces en mode debug pour les classes java du package "mondossierweb" |
enablePush showLoadingIndicator | Configuration du Push :
|
| EnablePdfSecurity | Activer la sécurité sur les pdf générés par l'application (pdf encryption) : crypte le contenu du PDF à l'aide d'un mot de passe de propriétaire généré aléatoirement pour empêcher sa modification avec Acrobat Reader. |
pdf.sign.keystore.path pdf.sign.password pdf.sign.creator pdf.sign.reason pdf.sign.location pdf.sign.contact | Paramètres pour la signature électronique des pdf, respectivement :
La signature électronique par un certificat validé par une autorité de certification (le certificat de l'université) permet d'assurer l'authenticité du document. A l'ouverture du document avec Acrobat Reader il est possible de consulter le certificat et son authenticité (si validé par une autorité de certification). Bien sûr, un document signé ne peut pas être modifié. La signature est plus sécurisée que l'encryption ci-dessus. |
pdf.sign.alt.tsa.url pdf.sign.alt.tsa.username pdf.sign.alt.tsa.password pdf.sign.alt.tsa.tokensize | Paramètre de la Time Stamp Authority (TSA) pour une signature compatible ALT : Nécessité de posséder un certificat délivré par une authentité de certification externe. La signature ALT doit être activée dans l'adminView (onglet PDF)
|
mail.smtpHost mail.smtpPort mail.from mail.to mail.startDisabling mail.stopDisabling liste.erreur.a.ignorer | Paramètres pour l'envoi des mails d'erreur, respectivement :
|
param.elasticsearch.url param.elasticsearch.port param.elasticsearch.cluster param.elasticsearch.index param.elasticsearch.index.champrecherche param.elasticsearch.index.champcodeobjet param.elasticsearch.index.champversionobjet param.elasticsearch.index.champlibelleobjet | Configuration de la connexion a ElasticSearch
Par convention, le type des objets doit être dans l'attribut ElasticSearch nommé "_type". Valeurs possible : CMP, VET, ETU, ELP L'implémentation d'ElasticSearch au sein de monDossierWeb dépend de la version installée. Pour changer le version utilisée et passer en v1, il faut partir du package source et modifier le pom.xml (voir doc Personnalisation) |
| recherche.autocompletion.elp | Configuration de la recherche rapide
|
param.apogee.mail.annuaire emailConverter.implementation | Configuration de la récupération du mail de l'étudiant
|
codetuFromLogin.implementation loginFromCodetu.implementation | Configuration de la récupération des identifiants Apogée d'un étudiant
|
| etatcivil.nom.affichage | Affichage du nom des étudiants
|
| resultat.implementation | Configuration de la classe chargée de la récupération des notes et résultat d'un étudiant dans Apogée |
| serveurphoto.implementation | Configuration de la récupération des photos
|
google.analytics.account piwik.tracker.url piwik.site.id | Configuration de la plateforme web analytics (facultatif). Google Analytics ou Piwik. Paramètres de Google Analytics, optionnel respectivement :
Paramètres de piwik, optionnel (https://fr.piwik.org/), respectivement :
|
2.2.1 Paramétrage des logs
Le fichier logback-mdw.xml (logback.xml en mdw 1.x) est livré avec une configuration par défaut des logs.
Il définit notamment l'historisation des accès dans un fichier mondossierweb-security.log avec les informations suivantes : login, IP, profil (student ou teacher) , numéro étudiant si c'est un étudiant, accès ou non possible à l'adminView.
Il est tout à fait possible de modifier ce fichier (il faudra alors le faire à chaque installation d'une nouvelle version).
Par exemple, pour supprimer les logs d'accès, il suffit de supprimer le bloc logger name="fr.univlorraine.mondossierweb.security" ou de lui assigner un level "error".
2.2.1 Paramétrage favicon
- SOLUTION 1 : dans le répertoire WEB-INF\classes\VAADIN\themes\valo-ul\ placer le fichier favicon.ico de votre établissement.
- SOLUTION 2 : dans le répertoire src\main\ressources\VAADIN\themes\valo-ul\ placer le fichier favicon.ico de votre établissement.
2.3 Paramétrage des webservices Apogée
Copier le fichier configUrlServices.sample.properties et renommer le en configUrlServices.properties puis éditer le.
Suivant le choix de la solution dans la partie 2.1, le fichier configUrlServices.sample.properties se trouve :
- SOLUTION 1 : dans /WEB-INF/classes/
- SOLUTION 2 : dans /src/main/resources/
A partir de la version 1.5.2
Renseigner :
- Les URLs des WebServices Apogée utilisés par l'application
- OPTIONNEL Les informations d'authentification aux WebServices Apogée si nécessaire (dépend de votre installation des WebServices Apogée)
- Il est possible de paramétrer un user différent par service.
- OPTIONNEL Des headers si vous en avez l'utilité :
- Il est possible de paramétrer des headers pour chaque service sous la forme : api.header.NomDuService.NomDuHeader = ValeurDuHeader
- L'exemple ci-dessous correspond aux headers nécessaires pour utiliser l'API Manager "Gravitee".
# WebServices administratifMetier.urlService=https://apo-ws.univ.fr/administratifMetier etudiantMetier.urlService=https://apo-ws.univ.fr/etudiantMetier pedagogiqueMetier.urlService=https://apo-ws.univ.fr/pedagogiqueMetier geographieMetier.urlService=https://apo-ws.univ.fr/geographieMetier offreFormationMetier.urlService=https://apo-ws.univ.fr/offreFormationMetier #Header api.header.administratifMetier.X-Gravitee-Api-Key = xxxxxx-xxxxxx-xxxx-xxxxx api.header.etudiantMetier.X-Gravitee-Api-Key = xxxxxx-xxxxxx-xxxx-xxxxx api.header.pedagogiqueMetier.X-Gravitee-Api-Key = xxxxxx-xxxxxx-xxxx-xxxxx api.header.geographieMetier.X-Gravitee-Api-Key = xxxxxx-xxxxxx-xxxx-xxxxx api.header.offreFormationMetier.X-Gravitee-Api-Key = xxxxxx-xxxxxx-xxxx-xxxxx #Authentification WS Apogée etudiantMetier.apo-ws-user = userEtudiant etudiantMetier.apo-ws-pwd = *******
Versions antérieures à la 1.5.2
SOLUTION 2 : Il faut également ajouter la librairie des WebServices Apogée dans le répertoire correspondant à la version utilisée (cf artifactId 'apo-webservicesclient' dans le pom.xml) sous src\main\resources\repository\gouv\education\apogee\apo-webservicesclient\{version} afin que maven puisse trouver la librairie lors de la compilation.
Renseigner dans configUrlServices, les URLs des WebServices utilisés dans l'application :
# WebServices Dossier Etudiant administratifMetier.urlService=https://wsapogee.univ.fr/services/AdministratifMetier etudiantMetier.urlService=https://wsapogee.univ.fr/services/EtudiantMetier pedagogiqueMetier.urlService=https://wsapogee.univ.fr/services/PedagogiqueMetier geographieMetier.urlService=https://wsapogee.univ.fr/services/GeographieMetier # Web Services Référentiel offreFormationMetier.urlService=https://wsapogee.univ.fr/services/OffreFormationMetier # WebServices Dossier Etudiant administratifMetier.urlService.ssl=https://wsapogee.univ.fr/services/AdministratifMetier etudiantMetier.urlService.ssl=https://wsapogee.univ.fr/services/EtudiantMetier pedagogiqueMetier.urlService.ssl=https://wsapogee.univ.fr/services/PedagogiqueMetier geographieMetier.urlService.ssl=https://wsapogee.univ.fr/services/GeographieMetier # Web Services Référentiel offreFormationMetier.urlService.ssl=https://wsapogee.univ.fr/services/OffreFormationMetier #SSL WS_SSL_MODE=false; WS_KEY_STORE_PATH=C:/client_keystore WS_CERTIF_STORE_PATH=C:/client_keystore WS_KEY_PASS=password WS_KEY_TYPE=jks
Tester les Web Services
Voir le chapitre "Tester les WebServices Apogée" sur cette documentation : https://www.esup-portail.org/wiki/x/BACUS
2.4 Requêtes SQL
Copier le fichier apogeeRequest.sample.xml et renommer le en apogeeRequest.xml.
Suivant le choix de la solution dans la partie 2.1, le fichier apogeeRequest.sample.xml se trouve :
- SOLUTION 1 : dans /WEB-INF/classes/
- SOLUTION 2 : dans /src/main/resources/
Si besoin, renseigner dans apogeeRequest.xml les requêtes à surcharger devant être utilisées par l'application.
En laissant le fichier tel qu'il est renseigné dans apogeeRequest.sample.xml, les requêtes SQL internes à l'application seront utilisées.
Sinon, plusieurs requêtes SQL sont modifiables. Dans apogeeRequest.sample.xml se trouve un exemple des requêtes tel qu'elles sont dans le code (java) de l'application.
Vous pouvez vous inspirer de ce fichier pour modifier ces requêtes. Les requêtes renseignées dans apogeeRequest.xml seront celles qui seront utilisées par l'application.
2.5 Base de données
La base de données (qui doit être préalablement créée vide) est automatiquement alimentée au démarrage de l'application.
2.6 ElasticSearch
Pour utiliser la vue Recherche Rapide de la partie enseignant de monDossierWeb, il faut disposer d'un elasticSearch. Il doit exposer un index stockant les objets Apogée que l'on souhaite proposer à la recherche rapide.
Les éléments obligatoires au bon fonctionnement de monDossierWeb
- Tous les objets doivent être dans un index unique.
- Par convention, le type de l'objet (ou document) doit se trouver dans l'attribut "_type". Il doit prendre les valeurs suivantes :
- CMP quand l'objet est de type composante.
- ELP quand l'objet est de type élément pédagogique.
- VET quand l'objet est de type version d'étape.
- ETU quand l'objet est de type étudiant.
- Les documents doivent également posséder :
- un attribut correspondant au libellé
- un attribut correspondant au code
- un attribut correspondant à la version
- un attribut qui va servir pour la recherche rapide :
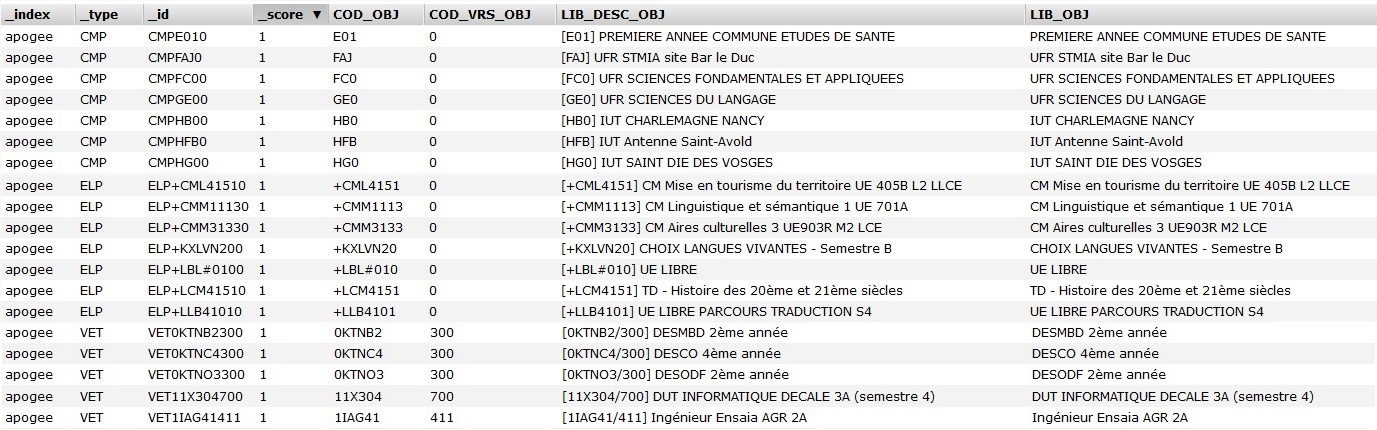
- Il peut s'agir simplement de l'attribut libellé ou encore d'un attribut concaténant le code et le libellé de l'objet. Pour exemple, à l'Université de Lorraine nous avons un attribut formaté comme suit : [CODE] LIBELLE
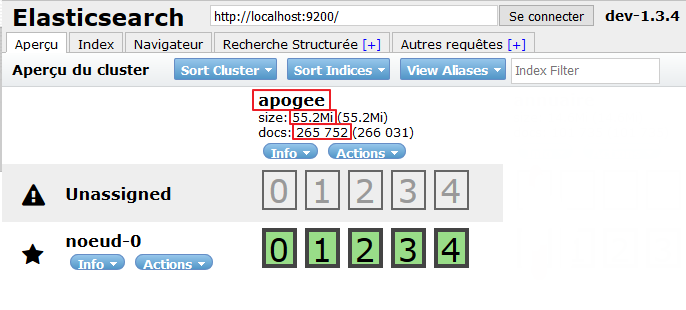
2.6.1 Exemple
Voici un exemple de l'index utilisé à l'Université de Lorraine :
2.6.2 Exemple d'installation d'elasticSearch et de l'index apogee
Rappel : La version d'ElasticSearch, peut varier tant que l'index reste paramétrable dans monDossierWeb (context.xml (cf 2.2 Paramétrage).)
Il est tout à fait possible de monter de version ou d'avoir un workflow de renseignement de l'index totalement différent tant que l'index contient les informations nécessaires à monDossierWeb.
Ce paragraphe n'est qu'un exemple pour aider les universités qui débuteraient avec ElasticSearch.
Important : L'implémentation d'ElasticSearch au sein de monDossierWeb dépend de la version installée. Pour changer le version utilisée et passer en v1, il faut partir du package source et modifier le pom.xml (voir doc Personnalisation)
ElasticSearch v1
Pour construire cet index d'exemple nous utilisons une "river", qui permet de créer un index à partir d'une requête SQL.
Attention : le plugin 'river' n'étant plus disponible depuis la v2.0 d'ElasticSearch, vous devez installer une version antérieure pour utiliser l'exemple ci-dessous.
NB : Le fonctionnement a été également validé avec elasticSearch en version 1.7.0.3 et le plugin river en version 1.5.0.5
1) Télécharger et dézipper Elasticsearch ( elasticsearch-1.3.4.official.zip )
Dans config/elasticsearch.yml décommenter et renseigner les paramètre cluster.name et node.name. Le cluster est à renseigner dans context.xml
2) démarrer Elasticsearch en lançant bin/elasticsearch depuis le répertoire d'installation,
3) Installer le plugin head :
./bin/plugin -install mobz/elasticsearch-head
Vous pouvez voir si le plugin est fonctionnel en vous rendant sur : http://localhost:9200/_plugin/head/ via votre navigateur web
4) Intaller le plugin river-jdbc pour Elasticsearch . Il suffit de lancer la commande suivante :
./bin/plugin --install river-jdbc --url http://xbib.org/repository/org/xbib/elasticsearch/plugin/elasticsearch-river-jdbc/1.3.4.7/elasticsearch-river-jdbc-1.3.4.7-plugin.zip
Au cas où, voici l'archive du plugin : elasticsearch-river-jdbc-1.3.4.7-plugin.zip
Pour lister les plugins installés :
./bin/plugin --list
5) Télécharger le driver oracle jdbc.
6) Copier le jar dans elasticsearch/plugins/river-jdbc
7) Redémarrer ElasticSearch
8) Créer la river avec le plugin Sense pour Chrome (le nom donné à l'index sera à renseigner dans context.xml):
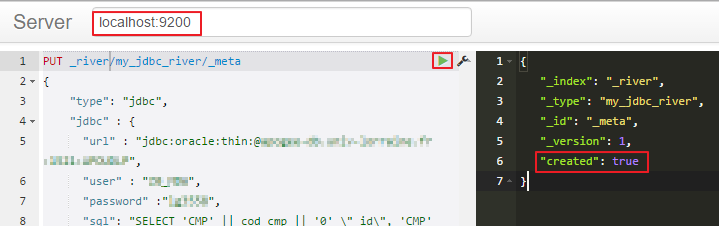
Exemple de création de river permettant de récupérer les composantes, VET, ELP, et étudiants valides sur n et n-1:
PUT _river/my_jdbc_river/_meta
{
"type": "jdbc",
"jdbc" : {
"url" : "jdbc:oracle:thin:@apogee.univ.fr:1521:APOGEE",
"user" : "userApogee",
"password" :"userPwd",
"sql": "SELECT 'CMP' || cod_cmp || '0' \"_id\", 'CMP' \"_type\", cod_cmp COD_OBJ, 0 COD_VRS_OBJ, '[' || cod_cmp || '] ' || lib_cmp LIB_DESC_OBJ, lib_cmp LIB_OBJ FROM composante UNION SELECT DISTINCT 'VDI' || vdi.cod_dip || vdi.cod_vrs_vdi \"_id\", 'VDI' \"_type\", vdi.cod_dip COD_OBJ, vdi.cod_vrs_vdi COD_VRS_OBJ, '[' || vdi.cod_dip || '/' || vdi.cod_vrs_vdi || '] ' || vdi.lib_web_vdi LIB_DESC_OBJ, vdi.lib_web_vdi LIB_OBJ FROM version_diplome vdi, diplome d, VDI_FRACTIONNER_VET vfv WHERE vdi.cod_dip = d.cod_dip and vfv.COD_DIP=d.cod_dip and vfv.COD_VRS_VDI=vdi.COD_VRS_VDI and vfv.DAA_FIN_RCT_VET > (select cod_anu - 2 from annee_uni where eta_anu_iae = 'O') UNION SELECT DISTINCT 'VET' || vet.cod_etp || vet.cod_vrs_vet \"_id\", 'VET' \"_type\", vet.cod_etp COD_OBJ, vet.cod_vrs_vet COD_VRS_OBJ, '[' || vet.cod_etp || '/' || vet.cod_vrs_vet || '] ' || vet.lib_web_vet LIB_DESC_OBJ, vet.lib_web_vet LIB_OBJ FROM version_etape vet, etape e, VDI_FRACTIONNER_VET vfv WHERE vet.cod_etp = e.cod_etp and vfv.COD_ETP=e.cod_etp and vfv.COD_VRS_VET=vet.COD_VRS_VET and vfv.DAA_FIN_RCT_VET > (select cod_anu - 2 from annee_uni where eta_anu_iae = 'O') UNION SELECT 'ELP' || cod_elp || '0' \"_id\",'ELP' \"_type\", cod_elp COD_OBJ, 0 COD_VRS_OBJ,'[' || cod_elp || '] ' || lib_elp LIB_DESC_OBJ, lib_elp LIB_OBJ FROM element_pedagogi e UNION select 'ETU' || IND.COD_ETU || '' \"_id\", 'ETU' \"_type\",CAST(IND.COD_ETU as VARCHAR2(40)) COD_OBJ, 0 COD_VRS_OBJ, '[' || IND.COD_ETU || '] ' || IND.LIB_PR1_IND || ' ' || NVL(IND.LIB_NOM_USU_IND,IND.LIB_NOM_PAT_IND) LIB_DESC_OBJ, IND.LIB_PR1_IND || ' ' || NVL(IND.LIB_NOM_USU_IND,IND.LIB_NOM_PAT_IND) LIB_OBJ from individu ind, INS_ADM_ANU iaa where IAA.COD_IND=ind.COD_IND and IND.COD_ETU is not null and IAA.COD_ANU > (select cod_anu - 2 from annee_uni where eta_anu_iae = 'O')",
"index" : "apogee"
}
}
A noter que les "river" peuvent être automatisés pour mettre à jour l'index régulièrement. Exemple :
PUT _river/my_jdbc_river/_meta
{
"type": "jdbc",
"jdbc" : {
"url" : "jdbc:oracle:thin:@apogee.univ.fr:1521:APOGEE",
"user" : "userApogee",
"password" :"userPwd",
"schedule": "0 0/15 5-23 * * ?",
"sql": "REQUETE SQL SUR MESURE",
"index" : "apogee"
}
}
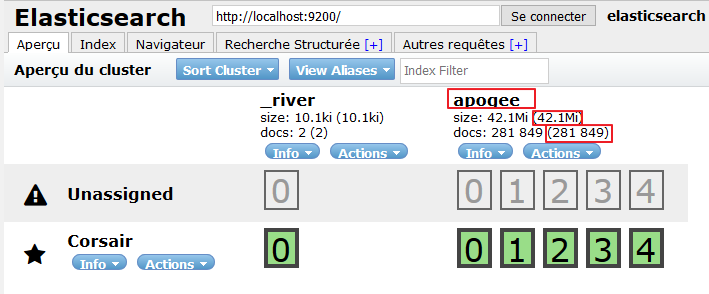
On peut voir sur http://localhost:9200/_plugin/head/ que l'index est créé est renseigné
ElasticSearch v2
Pour construire cet index d'exemple nous utilisons logstash, qui permet de créer un index à partir d'une requête SQL.
1) Télécharger et dézipper Elasticsearch ( elasticsearch-2.3.4.zip )
Dans config/elasticsearch.yml décommenter et renseigner les paramètre cluster.name et node.name. Le cluster est à renseigner dans context.xml
2) démarrer Elasticsearch en lançant bin/elasticsearch depuis le répertoire d'installation,
3) Installer le plugin head :
./bin/plugin -install mobz/elasticsearch-head
Vous pouvez voir si le plugin est fonctionnel en vous rendant sur : http://localhost:9200/_plugin/head/ via votre navigateur web.
Pour lister les plugins installés :
./bin/plugin list
4) Télécharger Logstash ( logstash-2.3.4.zip ) et le dézipper aux côtés d'ElasticSearch.
5) Télécharger le driver oracle jdbc.
6) Copier le jar dans le répertoire lib de logstash
7) Depuis le répertoire bin de logstash, lancer la commande suivante pour installer le plugin "input-jdbc" :
./plugin install logstash-input-jdbc
En y configurant :
- l'accès à Apogée,
- le driver utilisé
- le nom de l'index (le nom donné à l'index sera à renseigner dans context.xml de MonDossierWeb).
- l'url d'accès à l'elasticSearch
A noter que le plugin peut être automatisé pour mettre à jour l'index régulièrement. Pour cela il suffit d'ajouter un scheduler. Exemple :
... jdbc_driver_class => "Java::oracle.jdbc.driver.OracleDriver" schedule => "0 5-23 * * *" statement => "SELECT ...
9) Puis, depuis le répertoire bin, de logstash :
./logstash -f ../../apogee-test.conf
L'idéal est de l'ajouter dans un script de démarrage juste après la commande de démarrage d'ES .
On peut voir sur http://localhost:9200/_plugin/head/ que l'index est créé et renseigné