...
2.6.2 Exemple d'installation d'elasticSearch et de l'index apogee
| Info |
|---|
Rappel : La version d'ElasticSearch, peut varier tant que l'index reste paramétrable dans monDossierWeb (context.xml (cf 2.2 Paramétrage).) Il est tout à fait possible de monter de version ou d'avoir un workflow de renseignement de l'index totalement différent tant que l'index contient les informations nécessaires à monDossierWeb. Ce paragraphe n'est qu'un exemple pour aider les universités qui débuteraient avec ElasticSearch. |
ElasticSearch v1
Pour construire cet index d'exemple nous utilisons une "river", qui permet de créer un index à partir d'une requête SQL.
| Avertissement |
|---|
Attention : le plugin 'river' n'étant plus disponible depuis la v2.0 d'ElasticSearch, vous devez installer une version antérieure pour utiliser l'exemple ci-dessous. NB : Le fonctionnement a été également validé avec elasticSearch en version 1.7.0.3 et le plugin river en version 1.5.0.5 |
| Info |
|---|
Il est tout à fait possible de monter de version ou d'avoir un workflow de renseignement de l'index totalement différent tant que l'index contient les informations nécessaires à monDossierWeb. Ce paragraphe n'est qu'un exemple pour aider les universités qui débuteraient avec ElasticSearch. |
1) Télécharger 1) Télécharger et dézipper Elasticsearch ( elasticsearch-1.3.4.official.zip )
...
3) Installer le plugin head :
| Bloc de code |
|---|
./bin/plugin -install mobz/elasticsearch-head |
Vous pouvez voir si le plugin est fonctionnel en vous rendant sur : http://localhost:9200/_plugin/head/ via votre navigateur web
4) Intaller le plugin river-jdbc pour Elasticsearch . Il suffit de lancer la commande suivante :
| Bloc de code |
|---|
./bin/plugin --install river-jdbc -- |
...
url http://xbib.org/repository/org/xbib/elasticsearch/plugin/elasticsearch-river-jdbc/1.3.4.7/elasticsearch-river-jdbc-1.3.4.7-plugin.zip |
Au cas où, voici l'archive du plugin : elasticsearch-river-jdbc-1.3.4.7-plugin.zip
Pour lister les plugins installés :
| Bloc de code |
|---|
./bin/plugin --list |
5) Télécharger le driver oracle jdbc.
...
On peut voir sur http://localhost:9200/_plugin/head/ que l'index est créé est renseigné
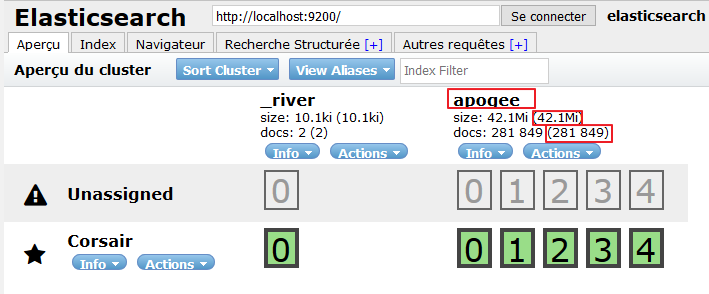
ElasticSearch v2
Pour construire cet index d'exemple nous utilisons logstash, qui permet de créer un index à partir d'une requête SQL.
1) Télécharger et dézipper Elasticsearch ( elasticsearch-2.3.4.zip )
Dans config/elasticsearch.yml décommenter et renseigner les paramètre cluster.name et node.name. Le cluster est à renseigner dans context.xml
2) démarrer Elasticsearch en lançant bin/elasticsearch depuis le répertoire d'installation,
3) Installer le plugin head :
| Bloc de code |
|---|
./bin/plugin -install mobz/elasticsearch-head |
Vous pouvez voir si le plugin est fonctionnel en vous rendant sur : http://localhost:9200/_plugin/head/ via votre navigateur web.
Pour lister les plugins installés :
| Bloc de code |
|---|
./bin/plugin --list |
4) Télécharger Logstash ( elasticsearch-2.3.4.zip ) et le dézipper aux côté d'ElasticSearch.
5) Télécharger le driver oracle jdbc.
6) Copier le jar dans le répertoire lib de logstash
7) Depuis le répertoire bin de logstash, lancer la commande suivante pour installer le plugin "input-jdbc" :
| Bloc de code |
|---|
plugin install logstash-input-jdbc |
8) Dans le répertoire qui contient ElasticSearch et Logstash, créer un fichier apogee-test.conf à partir du fichier exemple suivant : apogee-test-exemple.conf
En configurant l'accès à Apogée, le driver utilisé ainsi que le nom de l'index (le nom donné à l'index sera à renseigner dans context.xml):
9) Puis depuis le répertoire bin de logstash :
| Bloc de code |
|---|
logstash -f ../../apogee-test.conf |