Introduction
Après maintenant quelques années d'utilisation dans différents établissements, Grouper d'Internet2 est à l'usage une solution satisfaisante de gestion de groupes.
D'architecture complexe mais complète, sa mise en place dans un établissement n'est pas des plus simples, mais une fois en fonctionnement, Grouper d'Internet2 est une solution qui se fait aprécier.
Son installation et sa configuration sont en effet complexes, à sa décharge Grouper est hautement configurable et peut s'adapter à des cas d'usages avancés et très variés.
Dès les prémices de l'installation plusieurs choix s'offrent à l'intégrateur : installation depuis Grouper Installer, depuis une archive, depuis les sources, ...
Les possibilités de configuration et de mises en place des synchros sont ensuite sujets également à bon nombre de variantes.
A côté de cela, l'uniformisation croissante de nos Systèmes d'Information (supann, openldap, shibboleth, férédation d'identités, CAS) ainsi que les expériences et retours des établissements ayant sauté le pas (cf Contributions d'établissements et présentations ESUP-Days n°20, ESUP-Days n°22, ...) nous ont conforté dans l'idée que nos installations de Grouper pouvaient être assez similaires dans nos établissements.
La gestion d'un package Grouper 'ESUP' nous parait cependant trop ambitieuse et à terme contre-productive.
Aussi avons-nous décidé d'élaborer une documentation se voulant simple, concise, efficace et répondant à un contexte d'usage très spécifique et restreint : usage simple constaté dans nos établissements jusque-là.
Pour faciliter l'installation de Grouper, ce document propose de partir d'un "fork" github de Grouper (correspondant initialement aux travaux de ocnfiguration de Grouper de l'Université de Paris1) à reparamétrer. Ce document vous indique ce qu'il faut reparamétrer et comment installer les services.
Une fois que vous avez une installation "simple" et fonctionnelle intégrée dans votre système d'information, libre à vous par la suite d'aller plus loin dans l'usage de Grouper.
Gouper peut cependant tout à fait convenir et rendre énormément de servicies dans un usage circonscrit comme proposé ici ; cette intégration ayant alors le mérite de rester relativement simple, de ne pas sortir des clous par rapport à ce qui se fait "basiquement" avec Grouper ; on retire alors les avantages d'une maintenance facilitée par exemple.
*Nous avons envisagé de refaire une VM sous virutalbox telle que proposée lors du Workshop Grouper 2.1.5 – 15/04/2014 – Paris Descartes.
Vu le temps de mise en place qu'une telle entreprise prend nous hésitons à nous lancer dans cette tâche. On hésite également à utiliser plutôt d'autres solutions telles que Vagrant, Docker ou Ansible ...
Plan du document
Version de Grouper
La version de Grouper actuellement triatée par ce document est la 2.3.0.
Contexte d'usage et intégration souhaitée de Grouper dans le SI de l'établissement.
Le contexte d'usage et l'intégration de Grouper dans le système d'information de l'établissement est contraint de cette façon :
- authentification shibboleth sur les interfaces web Grouper - même si ici seuls les personnels de l'établissement sont amenés à s'authentifier sur celles-ci
- le LDAP de l'établissement est un openldap basé sur les recommandations (et schéma) Supann
- les potentiels membres des groupes (sources des individus pour grouper) sont tous issus du LDAP de l'établissement et on utilise comme identifiant non pas leur uid ldap mais leur eppn (eduPersonPrincipalName)
les groupes sont poussés/synchronisés dans le Ldap comme groupOfNames ('plus supann' et ‘plus standard’ que les posixGroup) côté ou=groups et éventuellement (conseillé) memberOf côté ou=people (via un overlay) par Grouper
- la nomenclature des groupes dans ldap reprend la nomenclature hiérarchique des groupes de grouper - les ":" sont transormés en "." dans le passage de l'id de grouper au dn ldap
- les applications utilisant les groupes ne conversent pas avec Grouper mais avec LDAP (cf schéma ci-dessous)
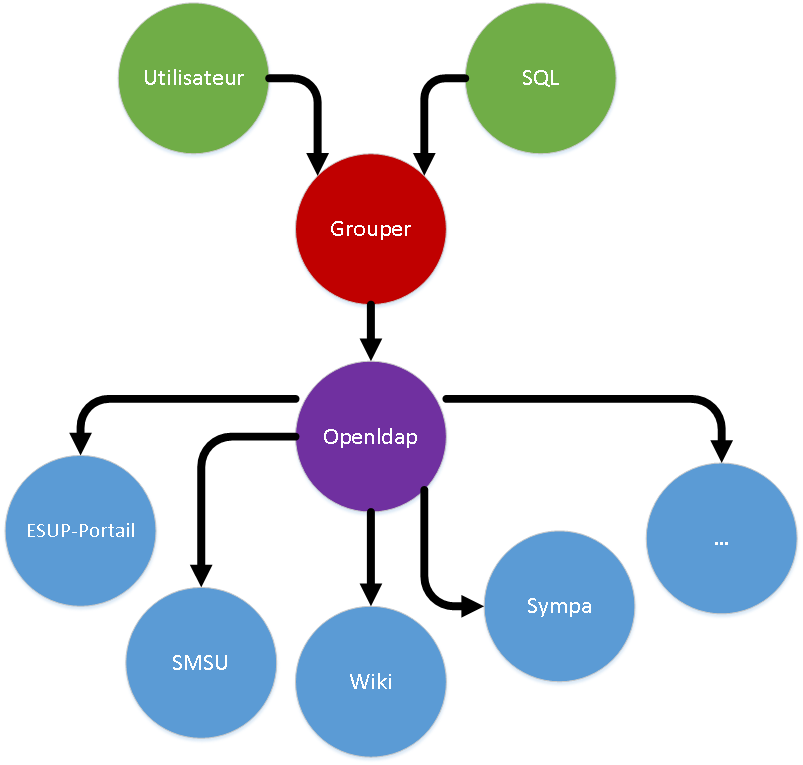
LDAP, prérequis/ajustements techniques
L'intégration de Grouper dans le Système d'Information est ici portée votre annuaire LDAP openldap construit selon les recommandations supann.
Des ajustements techniques doivent/peuvent être effectués (si ils n'ont pas déjà été faits).
overlay memberOf
Pour faciliter l'usage des groupes ldap dans les applications, il est intéressant de proposer l'information d'appartenance d'un individu à un groupe dans l'object de l'individu (supannPerson positionné dans ou=people) en plus de cette information portée par le groupOfNames (supannGroupe) lui-même.
Pour ce faire, l'idée est de mettre enplace le overlay memberOf.
Vous pouvez suivre cette documentation par exemple : http://idmoim.blogspot.fr/2014/05/enabling-memberof-attribute-in-openldap.html
Indexes
Pour optimiser les performances des applicatifs et de Grouper on vous conseille d'ajouter également des indexes, notamment sur
- eduPersoPrincipalName et memberOf côté ou=people
- member côte ou=groups
https://www.vincentliefooghe.net/content/ajout-dindex-sur-un-annuaire-openldap
Tri des attributs member
Sur des groupes de plusieurs milliers ou dizaines de milliers d'individus, il est impératif que l'attribut member soit trié, notamment pour que la suppression d'un individu à un groupe ne pose pas de problème.
Il faut donc demander à openldap de trier (olcSortVals) cet attribut member ... sous peine d'obtenir des temps de réponse catastrophiques, de récupérer des DB_LOCK_DEADLOCK au niveau de la base ldap, voir de mettre à terre votre serveur ldap !
Pour ce faire, vous pouvez suivre cette documentation :
Eléments techniques à installer sur le serveur qui héberge Grouper.
Java / Tomcat
Les service Grouper correspondent à des applications Java / Tomcat.
Ceux-ci fonctionnent avec un JDK 1.7 et Tomcat 6.
- vous pouvez prendre le JDK 1.7 distribué par Oracle (ou éventuellement la version openjdk 1.7 de votre distribution).
- pour Tomcat, prenez la dernière version 6 proposée - https://archive.apache.org/dist/tomcat/tomcat-6/v6.0.39/bin/
Java
Une fois je Java de téléchargé et d'installé (par exemple dans /usr/local), utilisez un lien symbolique /usr/local/jdk1.7 -> /usr/local/jdk1.7.0_79 pour faciliter les mises à jour éventuelles.
On édite un fichier /opt/grouper-env qui est un fichier d'environnement utilisé par les différents sscripts de démarrage de service et par un utilisateur 'grouper' (à créer) sous lequel on travaille (lancement du tomcat, scruipts de synchro, client shell grouper).
#!/bin/sh JAVA_HOME=/usr/local/jdk1.7 ANT_HOME=/usr/local/apache-ant EDITOR=emacs JAVA_OPTS="-Dgrouper.home=/opt/grouper-univrouen/grouper -Xms1512m -Xmx1512m -XX:MaxPermSize=512m -Djavax.net.ssl.trustStore=/opt/cacerts-vincent-121213.trustore -Djavax.net.ssl.trustStorePassword=azerty -XX:+CMSClassUnloadingEnabled -XX:+CMSPermGenSweepingEnabled -XX:-DoEscapeAnalysis"
Pour faciliter la prise en compte de ce fichier d'environnement dans un environnement bash, on réalise également un fichier /opt/env.sh :
#!/bin/sh set -o allexport source /opt/grouper-env PATH=$PATH:$JAVA_HOME/bin:$ANT_HOME/bin set +o allexport
Ainsi dans ~grouper/.bashrc en fin de fichier on ajoute :
. /opt/env.sh
Tomcat
Dézippez le tomcat dans /opt et faites le appartenir à un utilisateur 'grouper'.
Un lien symbolique est fait /opt/tomcat-grouper -> /opt/apache-tomcat-6.0.35 - on utilise ensuite /opt/tomcat-grouper comme chemin d'accès au tomcat dans les fichiers de configuration.
Dans /opt/tomcat-grouper/conf/server.xml on ajoute dans la balise Server < Service < Host les 2 contextes suivants :
<Context docBase="/opt/grouper-esup/grouper-ui/dist/grouper" path="/grouper" reloadable="false"/> <Context docBase="/opt/grouper-esup/grouper-ws/grouper-ws/build/dist/grouper-ws" path="/grouper-ws" reloadable="false"/>
PostgreSQL
Grouper utilise une base de données SQL. Installer le serveur postgresql fourni par votre distribution puis crééez une base pour grouper :
create database grouper; create USER grouper with password 'esup'; grant ALL ON DATABASE grouper to grouper;
Apache et mod_shib
Comme pour la plupart des applications 'shibbolethisées', l'authentification/identification shibboleth est effectuée par Apache et le mod_shib.
Il faut donc configurer un SP shibboleth prêt à l'emploi pour Grouper et un virtualhost en https://grouper.univ-ville.fr
Différentes documentations peuvent vous aider :
- doc et tutos Renater : https://services.renater.fr/federation/docs/installation#installer_un_sp_shibboleth
- doc plus concise (mais plus tout à fait à jour par rapport aux versions de distributions) : https://aresu.dsi.cnrs.fr/spip.php?article188
Une fois le Virtualhost apache et SP shibbolth bien paramétré comme il se doit, on doit accéder et tester la bonne configuration de l'ensemble via une url du type : https://grouper.univ-ville.fr/secure
Votre fichier de configuration Apache pouvant ressembler à cela :
<VirtualHost *:80>
ServerName grouper.univ-ville.fr
ServerAlias grouper
ServerAdmin dsi@univ-ville.fr
ServerSignature Off
LogLevel warn
ErrorLog /var/log/apache2/error.log
CustomLog /var/log/apache2/access.log combined
RewriteEngine On
RewriteRule ^(.*) https://grouper.univ-ville.fr$1 [L,R]
</VirtualHost>
<VirtualHost *:443>
ServerName grouper.univ-ville.fr
ServerAlias grouper
ServerAdmin dsi@univ-ville.fr
ServerSignature Off
LogLevel warn
ErrorLog /var/log/apache2/error.log
CustomLog /var/log/apache2/access.log combined
ErrorDocument 503 /503/index.html
ProxyPass /503 !
RewriteEngine On
RewriteCond %{HTTP_HOST} !^grouper.univ-ville.fr$
RewriteRule ^(.*) https://grouper.univ-ville.fr [L,R,NE]
RewriteRule ^/$ /grouper [L,R,NE]
SSLEngine on
SSLCertificateFile /etc/pki/tls/certs/localhost.crt
SSLCertificateKeyFile /etc/pki/tls/private/localhost.key
SSLCertificateChainFile /etc/pki/tls/certs/server-chain.crt
ProxyPass /Shibboleth.sso !
ProxyPass /secure !
ProxyPass /wsgroups !
ScriptAlias /secure /var/www/printenv.pl
<Location /secure>
AuthType shibboleth
ShibRequestSetting requireSession 1
require shib-session
ShibUseHeaders On
</Location>
<Location /grouper>
AuthType shibboleth
ShibRequestSetting requireSession 1
require shib-session
ShibUseHeaders On
</Location>
ProxyPass / ajp://localhost:8009/ ttl=10 timeout=3600 loadfactor=100 retry=1
</VirtualHost>
Grouper ESUP
Le 'fork' ESUP est sera (en cours) disponible https://github.com/EsupPortail/grouper-esup
Il consiste en la configuration de Grouper pour fonctionner de la manière décrite ci-dessus : ldap, shibboleth, postgresql, etc.
Cette version ('fork') ESUP est basée sur le tag GROUPER_2_3_0. Aussi l'usage de git vous permet d'identifier les modifications apportées ("configurations").
Cette version correspond à une véritable installation de Grouper dans un établissement, nous avons simplement renommé les noms des serveurs, changé les mots de passe, ...
Récupération de la version Grouper d'Esup
cd /opt git clone https://github.com/EsupPortail/grouper-esup.git
Modifications apportées
La commande suivant vous permet d'avoir une bonne idée des fichiers modifiés ou ajoutés :
cd /opt/grouper-esup git diff GROUPER_2_3_0 --name-only | grep -v jar
Mis à part les .gitignore, il vous faudra modifier une bonne partie de ces fichiers
grouper-ui/.gitignore grouper-ui/conf/.gitignore grouper-ui/conf/grouper-ui.properties grouper-ui/conf/grouperText/grouper.text.en.us.base.properties grouper-ui/conf/grouperText/grouper.text.fr.fr.properties grouper-ui/webapp/WEB-INF/struts-config.xml grouper-ui/webapp/WEB-INF/web.ajax.xml grouper-ui/webapp/WEB-INF/web.core.xml grouper-ui/webapp/grouperExternal/public/assets/images/logo_univ-ville.png grouper/.gitignore grouper/bin/export-modified-groups-to-LDAP grouper/bin/grouper-loader-daemon grouper/bin/grouper-loader-problem-with-subjectIdentifier.cgi grouper/bin/gsh grouper/bin/gsh-psp-bulkSync grouper/bin/sync-grouper-loader-group-and-export-to-LDAP grouper/bin/sync-grouper-loader-group-and-export-to-LDAP.cgi grouper/build.properties grouper/conf/ehcache.xml grouper/conf/grouper-loader.properties grouper/conf/grouper.client.properties grouper/conf/grouper.hibernate.properties grouper/conf/grouper.properties grouper/conf/ldap.properties grouper/conf/log4j.properties grouper/conf/morphString.properties grouper/conf/psp-internal.xml grouper/conf/psp-resolver.xml grouper/conf/psp-services.xml grouper/conf/psp.xml grouper/conf/server.properties grouper/conf/sources.xml grouper/ext/lib/temp.txt
Tâches d'exploitation
Scipts de démarrage
L'installation des services postgresql, apache, sp shibboleth ont dû engendrer l'ajout des scripts de démarrages (initd/systemctl/systemd).
Il faut y ajouter les services ajoutés 'manuellement'. Sous Centos 7 on a ainsi :
- /etc/systemd/system/multi-user.target.wants/tomcat-grouper.service
# Systemd unit file for tomcat [Unit] Description=Apache Tomcat Web Application Container After=syslog.target network.target [Service] Type=forking EnvironmentFile=/opt/grouper-env Environment=CATALINA_PID=/opt/tomcat-grouper/temp/tomcat.pid Environment=CATALINA_HOME=/opt/tomcat-grouper ExecStart=/opt/tomcat-grouper/bin/startup.sh ExecStop=/bin/kill -15 $MAINPID User=grouper Group=grouper [Install] WantedBy=multi-user.target
- /etc/systemd/system/multi-user.target.wants/grouper-loader-daemon.service
# Systemd unit file for grouper-loader-daemon [Unit] Description=Synchro incrementale grouperloader (bases de données) vers grouper After=syslog.target network.target [Service] EnvironmentFile=/opt/grouper-env ExecStart=/opt/grouper-univrouen/grouper/bin/grouper-loader-daemon User=grouper Group=grouper [Install] WantedBy=multi-user.target
/etc/systemd/system/multi-user.target.wants/export-modified-groups-to-LDAP.service
# Systemd unit file for export-modified-groups-to-LDAP [Unit] Description=Synchro incrementale grouper vers ldap After=syslog.target network.target postgresql.service [Service] EnvironmentFile=/opt/grouper-env ExecStart=/opt/grouper-univrouen/grouper/bin/export-modified-groups-to-LDAP User=grouper Group=grouper [Install] WantedBy=multi-user.target
Backup de la BD
Pour sauvegarder votre base de données de manière consistante, ajoutez un dump postgresql dans /etc/crontab simplement pour que le dump soit fait avant le passage de votre robot de sauvegarde.
## Backup de la base Grouper 30 01 * * * postgres rm -rf /opt/backup/grouper-dump && pg_dump -b -f /opt/backup/grouper-dump grouper
Tâches CRON de synchronisation
Pour assurer les synchronisations au mieux, on ajoute également dans /etc/crontab :
15 * * * * grouper /opt/grouper-univrouen/grouper/bin/gsh-psp-bulkSync # redémarrage de grouper-loader-daemon.service pour prise en compte ajout/modif groupes dynamiques 00,30 * * * * root systemctl restart grouper-loader-daemon.service
Démarrage de Grouper et prise en main
Démarrage des services
systemctl restart tomcat-grouper.service
systemctl restart grouper-loader-daemon.service
systemctl restart export-modified-groups-to-LDAP.service
Peuplement du groupe etc:sysadmingroup
Une fois Grouper démarré, vous allez pouvoir l'utiliser via ses interfaces web directement. Pour ce faire cependant, vous avez besoin de vous déclarer comme administrateur de Grouper. Vous faites cela en démarrant un shell grouper ainsi :
/opt/grouper-esup/grouper/grouper$ ./bin/gsh.sh
gsh 2% addMember("etc:sysadmingroup", "testjus@univ-ville.fr")
Interface Web
Vous pouvez maintenant utiliser votre grouper et initier votre arborsence de groupes.
La page wiki des Contributions d'établissements pourront vous donner des idées.
Un usage simple peut être de scinder vos arborescences de groupes en trois ensemble ainsi :
- un ensemble des groupes constitués dynamiquement et issus de requêtes SQL
- un ensemble de groupes dédéiés à des applicatifs spécifiques
- un ensemble de groupes autre qui correspondra aux groupes ne rentrant pas dans les 2 ensembles précédents
Dans un tout premier temps, un groupe à créer peut être le groupe DSI qui sera membre de etc:sysadmingroup par exemple !